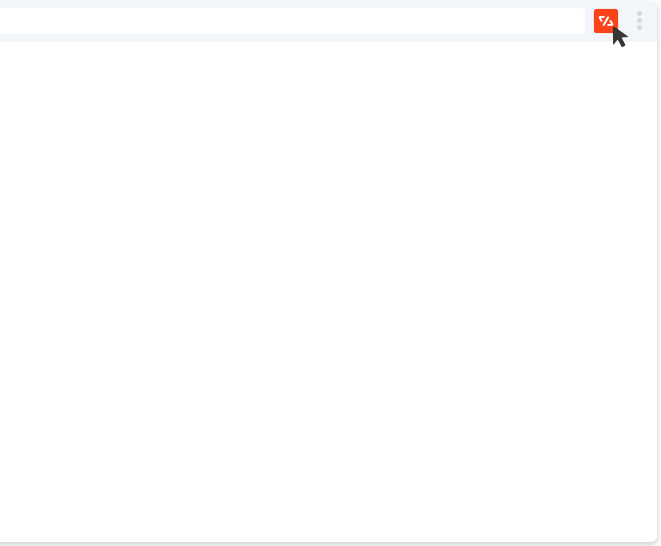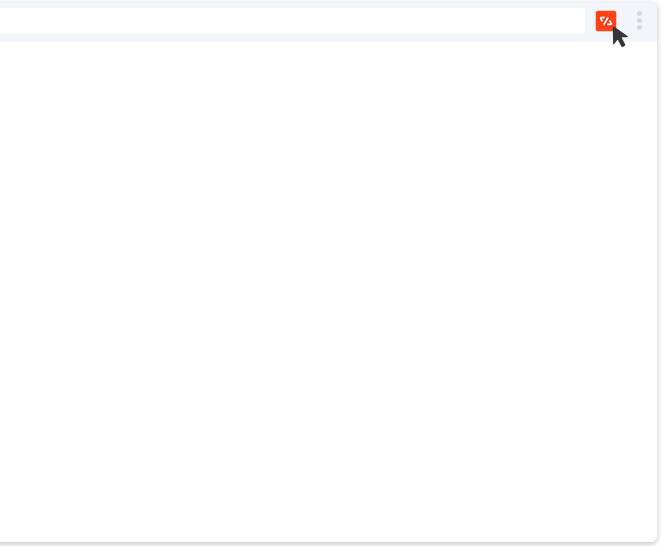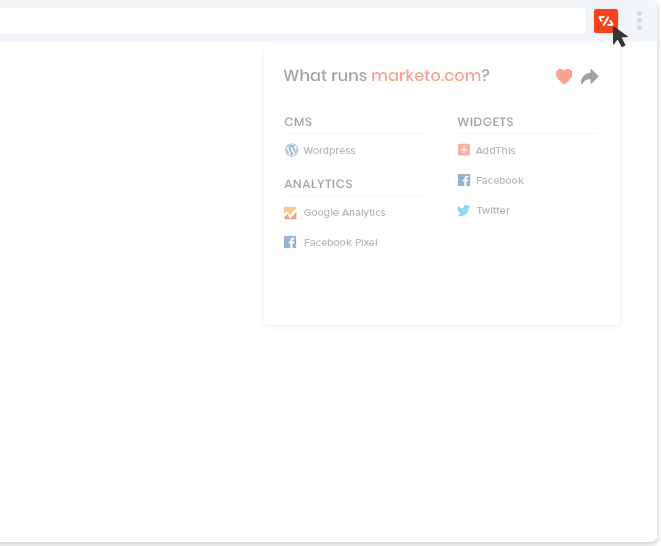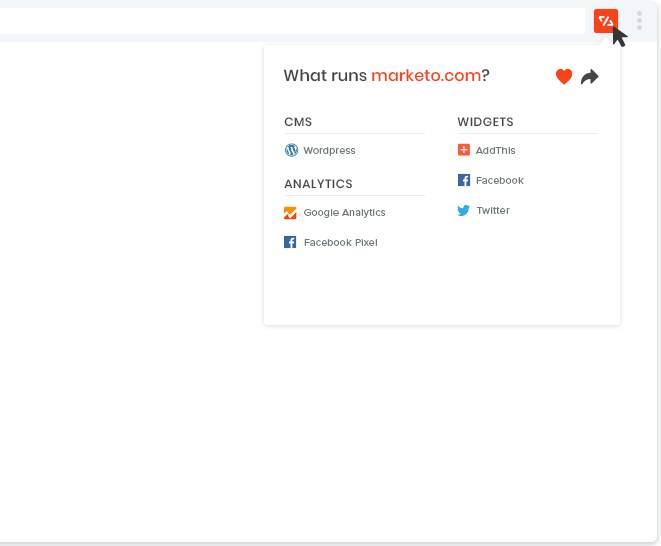
Mockaroo
1 | insert into MOCK_DATA (id, first_name, last_name, email, gender) values (1, 'Therine', 'Cawsey', 'tcawsey0@issuu.com', 'Female'); |
氏名を始め、住所や電話番号、IP アドレス等々、いろんなダミーデータが作成できます。作成できたデータは CSV だけでなく、直接 JSON と SQL 等に書き出せる機能は非常にありがたいです。無料ユーザでしたら、1000 件までしか作れませんが、一時的にテストをする目的であれば十分だと思います。ただ、英語しか対応していなく、日本語のデータ作成ができないことは難点として挙げられます。
avataaars generator
好みの問題もありますが、アバタ作成ツールの中、こちらの使い勝手が最も良いと考えています。シンプルでありながら、細かい調整ができ、イメージタグまで自動的に作成されるので、コピペの効率がグッと上がります(笑)。使ったことありませんが、React の専用ライブラリもあるようです。
Identicon generator
Identicon と言われたらピンっと来ない方が多いと思いますが、GitHub や SlackOverflow をよく利用している方であればこんなアイコンにはきっと出会ったことがあるはずです。
こちらのサービスはシンプルさをきわめたもので、余計な内容が全く入っていないと言っていいほどでしょう。パラメータが少ないゆえ基本的に GET クエリを弄るだけで話が済みますので、こっちの方が使いやすいと思いますよね。
Placehold
画像プレースホルダーを作成するサービスがいくつかもあり、正直大した差がないと感じています。こちらの方はテキストとそれのフォントや色まで指定できるから、地味に便利だと思い、利用し続けています。パラメータが直感的なので、迷うことがないと思います。
httpstat.us
テキストや画像だけではなく、ダミーレスポンスを入れたい場合がよくあります。そういう時はこちらのサービスを愛用しています。例えば、https://httpstat.us/202をリクエストすれば、202 Acceptedのレスポンスが戻って来ます。
1 | HTTP/1.1 202 Accepted |
sleepパラメータがサポートされているので、遅い処理をシミュレーションしたい場合だと非常に役に立ちます。
Webhook.site
こちらは最近見つけたサービスですが、痒い所に手が届いた感覚でした。Bot サービスを作成やテストする時、ダミーの Webhook が欲しくなったりします。今まではローカルにダミーサーバーを立てて、ngrok でセットアップするやり方を利用して来ましたが、このサービスを使った方がスムーズだったりします。なので、これからも活用していきたいと考えています。
さいごに
以上私が気に入ったモック用サービスを 6 つ紹介しました。おまけに、GitHub の Octocat を自作するサイトを合わせて紹介したいと思います。モックのプロフィール画像を作成するのに使えるかもしれませんので、興味ある方はぜひ遊んでみてください。
]]>